
After reading this blog, you will know How to Study for the CompTIA Data+ DA0-001 exam properly. Use the latest CompTIA Data+ DA0-001 practice questions to practice(https://www.pass4itsure.com/da0-001.html), master the official content, choose a variety of resources to learn, stay patient, and win
The CompTIA Data+ certification gives you the confidence to bring data analysis to life.
CompTIA Data+ certification release background
The latest 2022 Tech Jobs Report from the Computer Machinery Industry Association (CompTIA) shows that tech companies have added data analytics staff for the 24th consecutive month, and data analytics careers across the economy expanded in November.
In this context, CompTIA has recently released the Data+ certification in 2022.
The demand for data scientists also reflects the overall IT skills gap, and to meet the growing demand, CompTIA plans to expand its CompTIA data analytics certification resources significantly.
At present, with the prevalence of AI, the demand for data scientists is more vigorous, so it is more and more necessary to obtain the CompTIA Data+ certification through the DA0-001 exam.
CompTIA Data+ certification with high gold content and high recognition
CompTIA describes Data+ as “a data analytics career certification for professionals engaged in developing and facilitating data-driven business decision-making.”
To put it simply: data can help businesses make better, more informed decisions and reduce industry-related risks. The same is true for the non-commercial sector. We study (collect and analyze data) such as the best towns to live in, the best universities, what kind of car you want to buy, etc., and once we collect and analyze that information, we turn it into action, and in a way, we are all data analysts!
The CompTIA Data+ certification exam will focus on the candidate’s proficiency in the skills required for data-driven business decision-making, such as:
- Data concepts and contexts
- Operational data
- data analysis
- visualization
- Data governance, quality, and control
The details of the CompTIA Data+ DA0-001 exam need to be noted
Number of DA0-001 questions: Up to 90 questions
Published date: February 28, 2022
Exam question types: multiple-choice and performance-based
Exam duration: 90 minutes
Passing Score: 675 on a 100-900 scale
Prerequisites: CompTIA recommends 18-24 months of experience working as a report/business analyst, exposure to databases and analytical tools, basic understanding of statistics, and experience with data visualization
Languages: English, Japanese, Thai
Retirement: usually three years after launch
Suitable for the exam: Data Analyst, Business Data Analyst, Business Intelligence Analyst, Clinical Analyst, Market Analyst, Business Analyst, Report Analysis, Clinical Care Analysis, Financial Analyst, Human Resources Analyst, Marketing Specialist
Positions available after passing the exam: Data Architect, Data Analyst, Data Scientist, Business Analyst, Report Analyst, Operations Analyst
Closely related to the CompTIA Data+ certification is the same type of certification: SAS® Certified Specialist: Visual Business Analytics, Tableau Certified Data Analyst, Microsoft Certified: Data Analyst Associate
Useful resource links for studying for the CompTIA Data+ exam: https://www.comptia.org/certifications/data https://www.comptia.org/training/books/data-da0-001-study-guide https://www.comptia.org/training/certmaster-learn/data https://www.comptia.org/training/by-certification/comptia-data-training https://www.comptia.org/training/certmaster-practice/data https://www.comptia.org/continuing-education/renewothers/renewing-data-single
https://www.comptia.org/blog/comptia-data-your-questions-answered
The proper way to study for the DA0-001 exam
How to Prepare for the CompTIA Data+ Certification Exam? Reading, reviewing, and doing questions are the three essential parts of the exam, but what books to read, what materials to review, and which questions to practice have become the key to passing the exam.
The first step is to master the official content (CompTIA offers three excellent resources: CertMaster Learn, CertMaster Labs, and CertMaster Practice. CertMaster Learn: This comprehensive online learning resource covers every exam objective for CompTIA Data+. CertMaster Labs: This is a virtual lab that prepares you for the exam through hands-on practice and time feedback. CertMaster Practice: This is a powerful practice tool that helps you improve your skills and fill in your weaknesses by identifying knowledge gaps through practice. CertMaster Labs: This is a virtual lab that prepares you for the exam through hands-on practice and time feedback. ).
The second step is to get the latest CompTIA Data+ DA0-001 practice questions (available from Pass4itSure DA0-001 practice questions resources) to practice.
The third step is to choose a variety of resources (videos, books, discussion groups, online courses).
Finally, be patient and do plenty of practice.
Latest CompTIA Data+ DA0-001 practice questions
Provider: Pass4itSure
Free|Charged: Free
Number of Questions: 1-15
Last updated: free DA0-001 exam practice questions
Question 1:
SIMULATION
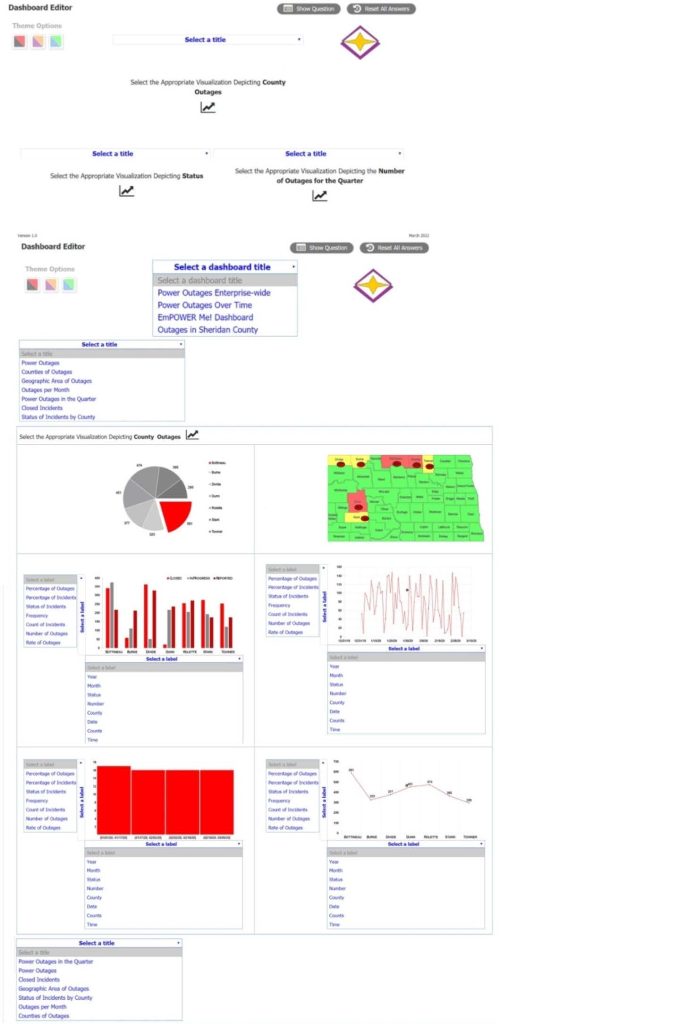
The director of operations at a power company needs data to help identify where company resources should be allocated in order to monitor activity for outages and restoration of power in the entire state. Specifically, the director wants to see the following:
*
County outages
*
Status
*
The overall trend of outages
INSTRUCTIONS:
Please, select each visualization to fit the appropriate space on the dashboard and choose an appropriate color scheme. Once you have selected all visualizations, please, select the appropriate titles and labels, if applicable. Titles and labels
may be used more than once.
If at any time you would like to bring back the initial state of the simulation, please click the Reset All button.
A. Check the answer in the explanation.
Correct Answer: A
Answer: Power outages This is a simulation question that requires you to create a dashboard with visualizations that meet the director\’s needs. Here are the steps to complete the task: Drag and drop the visualization that shows the county outages on the top left space of the dashboard. This visualization is a map of the state with different colors indicating the number of outages in each county.
You can choose any color scheme that suits your preference, but make sure that the colors are consistent and clear. For example, you can use a gradient of red to show the counties with more outages and green to show the counties with fewer outages. Drag and drop the visualization that shows the status of the outages on the top right space of the dashboard.
This visualization is a pie chart that shows the percentage of outages that are active, restored, or pending. You can choose any color scheme that suits your preference, but make sure that the colors are distinct and easy to identify. For example, you can use red for active, green for restored, and yellow for pending. Drag and drop the visualization that shows the overall trend of outages on the bottom space of the dashboard.
This visualization is a line graph that shows the number of outages over time. You can choose any color scheme that suits your preference, but make sure that the color is visible and contrasted with the background. For example, you can use blue for the line and white for the background. Select appropriate titles and labels for each visualization.
Titles and labels may be used more than once. For example, you can use “County Outages” as the title for the map, “Status” as the title for the pie chart, and “Trend” as the title for the line graph. You can also use “County”, “Number of Outages”, “Active”, “Restored”, “Pending”, “Time”, and “Number of Outages” as labels for the axes and legends of the visualizations.
Question 2:
Given the following customer and order tables:
Which of the following describes the number of rows and columns of data that would be present after performing an INNER JOIN of the tables?
A. Five rows, eight columns
B. Seven rows, eight columns
C. Eight rows, seven columns
D. Nine rows, five columns
Correct Answer: B
Explanation: This is because an INNER JOIN is a type of join that combines two tables based on a matching condition and returns only the rows that satisfy the condition. An INNER JOIN can be used to merge data from different tables that have a common column or a key, such as customer ID or order ID. To perform an INNER JOIN of the customer and order tables, we can use the following SQL statement:
This statement will select all the columns (*) from both tables and join them to the customer ID column, which is the common column between them. The result of this statement will be a new table that has seven rows and eight columns, as shown below:
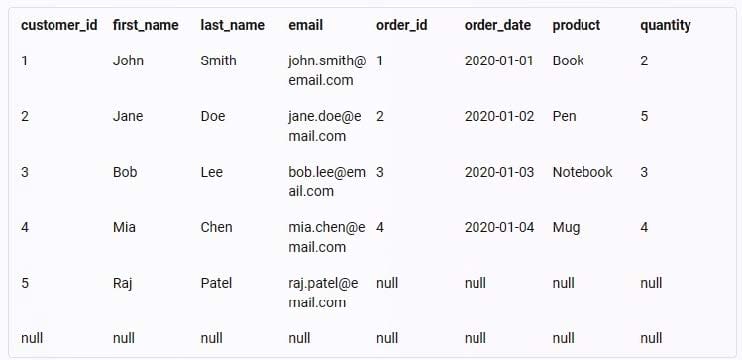
The reason why there are seven rows and eight columns in the result table is because:
There are seven rows because there are six customers and six orders in the original tables, but only five customers have matching orders based on the customer ID column. Therefore, only five rows will have data from both tables, while one
row will have data only from the customer table (customer 5), and one row will have no data at all (null values).
There are eight columns because there are four columns in each of the original tables, and all of them are selected and joined in the result table. Therefore, the result table will have four columns from the customer table (customer ID, first
name, last name, and email) and four columns from the order table (order ID, order date, product, and quantity).
Question 3:
What role in data governance is typically responsible for day-to-day oversight of data use?
A. Data processors.
B. Data custodians
C. Data owners.
D. Data stewards.
Correct Answer: D
Question 4:
A data scientist wants to see which products make the most money and which products attract the most customer purchasing interest in their company.
Which of the following data manipulation techniques would he use to obtain this information?
A. Data append
B. Data blending
C. Normalize data
D. Data merge
Correct Answer: B
The correct answer is B: Data blending. Data blending is combining multiple data sources to create a single, new dataset, which can be presented visually in a dashboard or other visualization and can then be processed or analyzed.
Enterprises get their data from a variety of sources, and users may want to temporarily bring together different datasets to compare data relationships or answer specific questions. The data append is incorrect. Data append is a process that involves adding new data elements to an existing database.
An example of a common data append would be the enhancement of a company\’s customer files. A data append takes the information they have, and matches it against a larger database of business data, allowing the desired missing data fields to be added.
Normalize data is incorrect. Data normalization is the process of structuring your relational customer database, following a series of normal forms. This improves the accuracy and integrity of your data while ensuring that your database is easier to navigate. The data merge is incorrect. Data merging is the process of combining two or more data sets into a single data set.
Question 5:
Given the diagram below:
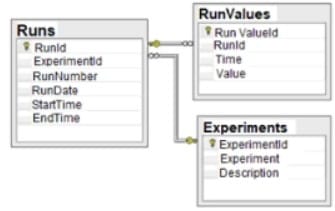
Which of the following data schemas shown?
A. Key-value pairs
B. Online transactional processing
C. Data Lake
D. Relational database
Correct Answer: D
A relational database is a type of database that organizes data into tables, where each table has a fixed number of columns and a variable number of rows. Each row in a table represents a record or an entity, and each column represents an attribute or a property of that entity. The tables are linked by common fields, called keys, which enable the database to establish relationships between the data.
A relational database schema is a diagram that shows the structure and organization of the tables, columns, keys, and constraints in a relational database. The diagram given in the question is an example of a relational database schema, as it shows two tables: “Runs” and “Experiments”, with their respective columns, data types, and primary keys. The “Runs” table also has a foreign key that references the “ExperimentId” column in the “Experiments” table, indicating a relationship between the two tables. Therefore, the correct answer is D. References: What is a database schema? | IBM, Database Schema – Javatpoint
Question 6:
A data analyst for a media company needs to determine the most popular movie genre. Given the table below:
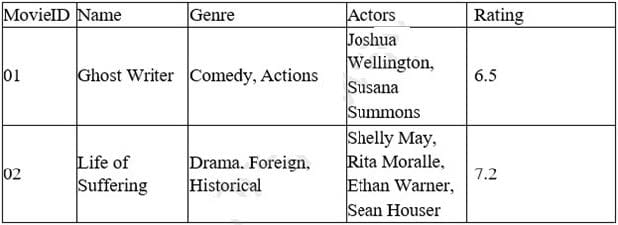
Which of the following must be done to the Genre column before this task can be completed?
A. Append
B. Merge
C. Concatenate
D. Delimit
Correct Answer: D
Explanation: The action that must be done to the Genre column before this task can be completed is delimited. Delimit is a process of separating or splitting a string of text into multiple parts based on a delimiter, which is a character or a sequence of characters that marks the boundary between the parts. For example, a comma (,) or a semicolon (;) can be used as a delimiter. In this case, the Genre column contains multiple genres for each movie, separated by commas.
To determine the most popular movie genre, the data analyst needs to delimit the Genre column by commas, so that each genre can be counted and compared separately. The other options are not relevant to this task, as they are related to combining or joining strings or tables, not separating them.
Append is a process of adding or attaching one string or table to the end of another string or table. Merge is a process of combining or joining two or more tables into one table based on a common column or key. Concatenate is a process of joining or linking two or more strings together into one string. Reference: [How to Split Text in Excel – Exceljet]
Question 7:
A data analyst wants to create “Income Categories” that would be calculated based on the existing variable “Income”. The “Income Categories” would be as follows:
Income category 1: less than $1.
Income category 2: more than $1 and less than $20,000.
Income category 3: more than $20,001 and less than $40,000.
Income category 4: more than $40,001.
Which of the following data manipulation techniques should the data analyst use to create “Income Categories”?
A. Data merge
B. Derived variables
C. Data blending
D. Data append
Correct Answer: B
The correct answer is B: Derived variables are variables that you create by calculating or categorizing variables that already exist in your data set. The data merge is incorrect. Data merging is the process of combining two or more data sets into a single data set. Data blending is incorrect. Data blending involves pulling data from different sources and creating a single, unique, dataset for visualization and analysis.
The data append is incorrect. A data append is a process that involves adding new data elements to an existing database.
Question 8:
A data analyst has been asked to derive a new variable labeled “Promotion_flag” based on the total quantity sold by each salesperson. Given the table below:
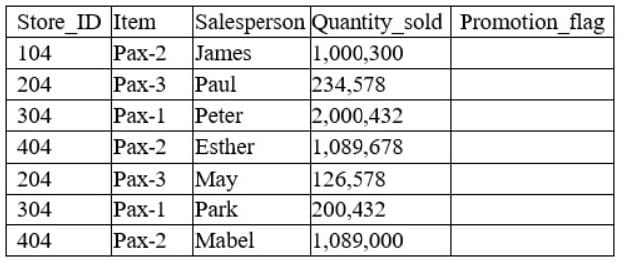
Which of the following functions would the analyst consider appropriate to flag “Yes” for every salesperson who has a number above 1,000,000 in the Quantity_sold column?
A. Date
B. Mathematical
C. Logical
D. Aggregate
Correct Answer: C
A logical function is a type of function that returns a value based on a condition or a set of conditions. For example, the IF function in Excel can be used to check if a certain condition is met, and then return one value if true, and another value if false. In this case, the data analyst can use a logical function to check if the Quantity_sold column is greater than 1,000,000, and then return “Yes” if true, and “No” if false. This would create a new variable called Promotion_flag that indicates whether the salesperson has sold more than 1,000,000 units or not.
References: CompTIA Data+ Certification Exam Objectives, Logical functions (reference)
Question 9:
Which of the following data sampling methods involves dividing a population into subgroups by similar characteristics?
A. Systematic
B. Simple random
C. Convenience
D. Stratified
Correct Answer: D
Explanation: Stratified sampling is a data sampling method that involves dividing a population into subgroups by similar characteristics, such as age, gender, income, etc. Then, a simple random sample is drawn from each subgroup. This method ensures that each subgroup is adequately represented in the sample and reduces the sampling error.
References: CompTIA Data+ Certification Exam Objectives, page 11.
Question 10:
Which of the following should be accomplished NEXT after understanding a business requirement for a data analysis report?
A. Rephrase the business requirement.
B. Determine the data necessary for the analysis.
C. Build a mock dashboard/presentation layout.
D. Perform exploratory data analysis.
Correct Answer: B
Explanation: Exploratory data analysis (EDA) is a process of examining and summarizing a dataset using various techniques, such as descriptive statistics, visualizations, correlations, outliers detection, and hypothesis testing. EDA can help
reveal the main characteristics, patterns, trends, and insights from the data, as well as identify any problems or issues with the data quality or structure. EDA is usually performed after understanding a business requirement for a data analysis report and before building a mock dashboard/presentation layout. Therefore, the correct answer is B.
References:
[What is Exploratory Data Analysis? | Definition and Examples], [Exploratory Data Analysis in Python]
Question 11:
A data analyst is designing a dashboard that will provide a story of sales and determine which site is providing the highest sales volume per customer The analyst must choose an appropriate chart to include in the dashboard. The following data is available: Which of the following types of charts should be considered?
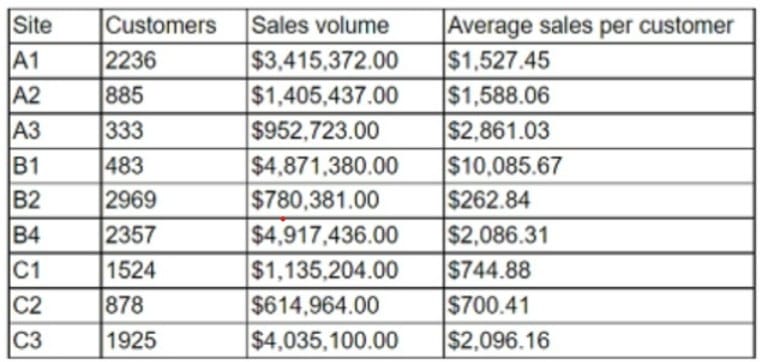
A. Include a line chart using the site and average sales per customer.
B. Include a pie chart using the site and sales to average sales per customer.
C. Include a scatter chart using sales volume and average sales per customer.
D. Include a column chart using the site and sales to average sales per customer.
Correct Answer: D
The best type of chart to display the data is D. Include a column chart using the site and sales to average sales per customer. A column chart is a good choice for comparing categorical data with numerical data, such as the site and sales to average sales per customer. A column chart can show the relative differences between the sites and highlight the site with the highest sales volume per customer.
A column chart can also be easily labeled and formatted to make the data clear and understandable. A line chart is not suitable for this data, because it is used to show trends or changes over time, which is not relevant for the site and sales to average sales per customer data. A line chart would also be confusing and misleading, as it would imply a connection or correlation between the sites that do not exist.
A pie chart is also not a good choice for this data, because it is used to show the proportion of a whole, not the comparison of different categories. A pie chart would also be difficult to read and interpret, as it would require labels or legends to identify the sites and their sales to average sales per customer. A pie chart would also not be able to show the exact values of the sales to average sales per customer, only their relative sizes.
A scatter chart is another inappropriate option for this data because it is used to show the relationship or correlation between two numerical variables, not between a categorical and a numerical variable. A scatter chart would also be cluttered and unclear, as it would plot each site as a point on a coordinate plane, without any labels or axes. A scatter chart would also not be able to show the differences or rankings between the sites and their sales to average sales per customer.
Question 12:
You are working with a dataset and want to change the names of categories that you used for different types of books.
What term best describes this action?
A. Recording.
B. Summarizing
C. Aggregating.
D. Filtering.
Correct Answer: A
Explanation: The term that best describes the action of changing the names of categories that you used for different types of books is recoding. Recoding is a process of transforming or modifying the values of a variable or a category to make them more meaningful, consistent, or accurate.
For example, you can recode the names of book genres from “Fiction”, “Non-Fiction”, “Biography”, etc. to “FIC”, “NF”, “BIO”, etc. to make them shorter and easier to use. Reference: Recoding Data – SPSS Tutorials – LibGuides at Kent State University
Question 13:
Consider this dataset showing the retirement age of 11 people, in whole years:
54, 54, 54, 55, 56, 57, 57, 58, 58, 60, 60
These tables show a simple frequency distribution of the retirement age data.
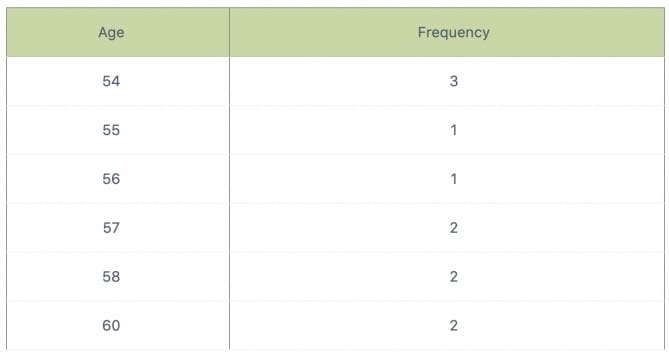
A. 56
B. 55
C. 57
D. 54
Correct Answer: D
A measure of central tendency (also referred to as measures of center or central location) is a summary measure that attempts to describe a whole set of data with a single value that represents the middle or center of its distribution. There
are three main measures of central tendency: the mode, the median, and the mean. Each of these measures describes a different indication of the typical or central value in the distribution.
What is the mode?
The mode is the most commonly occurring value in a distribution. The most commonly occurring value is 54, therefore the mode of this distribution is 54 years.
Question 14:
A data analyst was asked to create a chart that shows the relationship between study hours and exam scores for each student using the data sets in the table below: Which of the following charts would BEST represent the relationship between the variables?
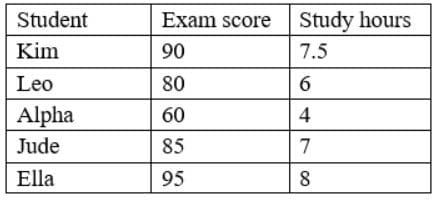
A. A histogram
B. A scatter plot
C. A heat map
D. A bar chart
Correct Answer: B
Explanation: This is because a scatter plot is a type of chart that shows the relationship between two variables for each observation or unit in a data set, such as study hours and exam scores for each student in this case. A scatter plot can be used to display and analyze the correlation, trend, or pattern among the variables, as well as identify any outliers or clusters in the data.
For example, a scatter plot can show if there is a positive, negative, or no correlation between study hours and exam scores, as well as show if there are any students who have unusually high or low exam scores compared to their study hours. The other charts are not the best charts to represent the relationship between the variables. Here is why:
A histogram is a type of chart that shows the frequency or the count of values in a single variable for different intervals or bins, such as exam scores for different ranges in this case. A histogram can be used to display and analyze the distribution, shape, or spread of the variable, as well as identify any gaps, peaks, or skewness in the data.
For example, a histogram can show if most students have high, low, or average exam scores, as well as show if any intervals have no students at all. A heat map is a type of chart that shows the intensity or the magnitude of values in two variables for different categories or groups, such as exam scores and study hours for different student names in this case.
A heat map can be used to display and analyze the variation, contrast, or comparison among the categories or groups, as well as identify any hot spots, cold spots, or gradients in the data. For example, a heat map can show which students have higher or lower exam scores and study hours than others, as well as show if there is a color pattern that indicates a relationship between exam scores and study hours.
A bar chart is a type of chart that shows the value or the amount of a single variable for different categories or groups, such as exam scores for different student names in this case. A bar chart can be used to display and analyze the comparison, ranking, or proportion among the categories or groups, as well as identify any differences, similarities, or outliers in the data.
For example, a bar chart can show which students have higher or lower exam scores than others, as well as show if any students have exceptionally high or low exam scores.
Question 15:
Samantha needs to share a list of her organization\’s top 50 customers with the VP of sales.
She would like to include the name of the customer, the business they represent, their contact information, and their total sales over the past year. The VP does not have any specialized analytics skills or software but would like to make some personal notes on the dataset.
What would be the best tool for Samantha to use to share this information?
A. Power BI.
B. Microsoft Excel.
C. Minitab.
D. SAS.
Correct Answer: B
Microsoft Excel.
This scenario presents a very simple use case where the business leader needs a dataset in an easy-to-access form and will not be performing any detailed analysis. A simple spreadsheet, such as Microsoft Excel, would be the best tool for
this job. There is no need to use a statistical analysis package, such as SAS or Minitab, as this would likely confuse the VP without adding any value. The same is true of an integrated analytics suite, such as Power BI.
CompTIA Data+ DA0-001 exam huge offer
Is there a discount for CompTIA Data+ certification DA0-001? Yes, go to the official website to get the top exam and training – save 39%. Pass4itSure CompTIA Data+DA0-001 exam question dumps resources are also available with code: “save10” to get a 10% discount.
Other Data Analytics Certifications for Beginners
What makes the DA0-001 exam unique: CompTIA Data+ is the only data analyst certification that covers foundational data analysis skills, assesses hands-on ability, and is vendor-agnostic and tool-agnostic.
If you want to try other data analytics certifications, you can try the following:
SAS® Certified Specialist: Visual Business Analytics: For beginners, the exam focuses on data analysts using SAS® Visual Analytics to analyze data and design reports.
Tableau Certified Data Analyst: For beginners, the exam focuses on analysts using Tableau to explore and deliver actionable insights to make business decisions by identifying data.
Microsoft Certified: Data Analyst Associate: Use Microsoft Power BI to design and build data models and enable analytics.
Summary:
In the big wave of AI around the world, the CompTIA Data+ DA0-001 certification is becoming more and more important, you need to get it the right way (download Pass4itSure new DA0-001 practice questions https://www.pass4itsure.com/da0-001.html Q&As: 215) to get it, don’t stick to one way in the learning process, try as many resources as possible, be patient, and believe in doing it, DA0-001 exam success must belong to you.
